接着上面的文章
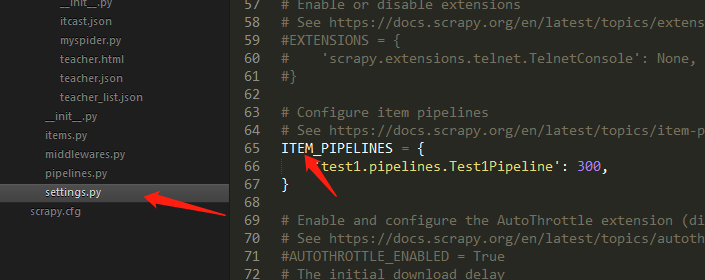
先在setting文件打开pipeline管道配置
写管道文件程序
import scrapy
from bs4 import BeautifulSoup as bs
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['janpn.com']
start_urls
链接:https://pan.baidu.com/s/177I6mxhRtZyozWYKKkelGw
提取码:81fg
导出json文件,但是中文是unicode码,可以用转码工具转码
继续上一篇文章
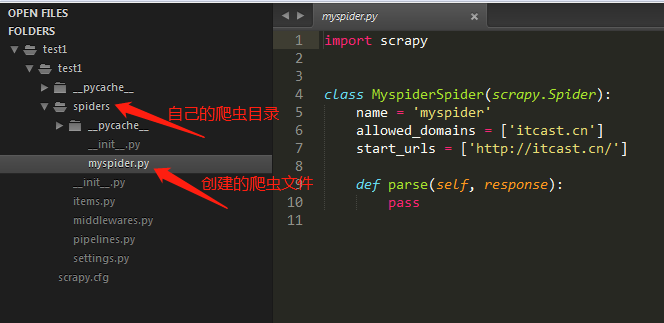
在爬虫文件myspider.py 写代码:
#爬虫名
name = 'itcast'
#允许爬的域名
#!/usr/bin/python
import re
import smtplib
from email.mime.text import MIMEText
from email.header import Header
from email.mime.multipart import MIMEMultipart
from email import encoders
f = open("C:\\Users\\Administrator\\Desktop\\email.txt","r") #设置文件对象
data = f.readlines() #直接将文件中按行读到list里,效果与方法2一样20
f.close() &nb