接着上面的文章
先在setting文件打开pipeline管道配置
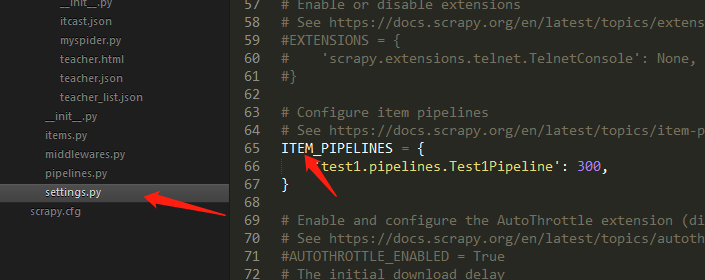
写管道文件程序
爬虫文件myspider.py
import scrapy
from test1.items import Test1Item
import json
class MyspiderSpider(scrapy.Spider):
#爬虫名
name = 'itcast'
#允许爬的域名
allowed_domains = ['itcast.cn']
#爬虫爬的url
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#apython']
def parse(self, response):
#with open("teacher.html","wb") as f:
# f.write(response.body)
#定义个集合存储爬虫数据
#teacherItem=[]
teacher_list=response.xpath('//div[@class="li_txt"]')
for i in teacher_list:
#xpath返回的一定是个列表.extract取出字符串,不然会直接打印对象字符串
name=i.xpath('./h3/text()')[0].extract()
title=i.xpath('./h4/text()')[0].extract()
info=i.xpath('./p/text()')[0].extract()
print(name)
print(title)
print(info)
#实例化一个item对象
item=Test1Item()
#通过yield传入管道
yield item
# item['name']=name
# item['title']=title
# item['info']=info
# teacherItem.append(item)
#return teacherItem
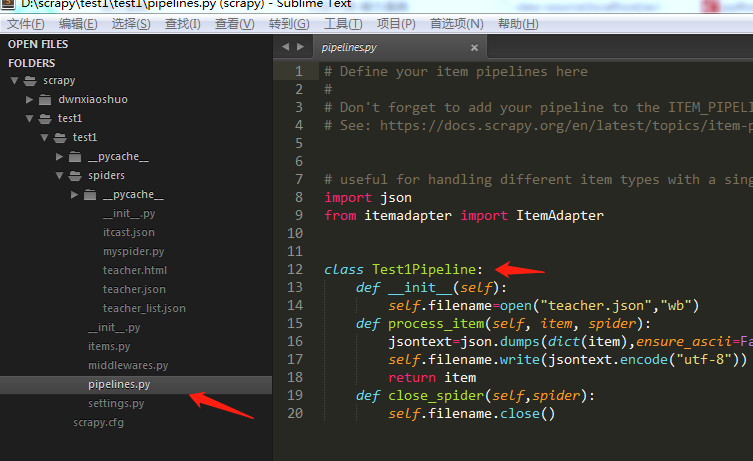
管道文件pipeline.py文件
import json
from itemadapter import ItemAdapter
class Test1Pipeline:
def __init__(self):
self.filename=open("teacher.json","wb")
def process_item(self, item, spider):
jsontext=json.dumps(dict(item),ensure_ascii=False)
self.filename.write(jsontext.encode("utf-8"))
return item
def close_spider(self,spider):
self.filename.close()
链接:https://pan.baidu.com/s/1Sk9XCK6WGWoHEUh3gX7sng
提取码:s2qh